How I built a Serverless Micro-Blogging Site Using Next.js and Fauna

Full-Stack Developer, Entrepreneur and Co-Founder of Coderplex.
Building https://coderplex.in
Checkout my portfolio at https://bhanuteja.dev
Authored in connection with the Write With Fauna program.
Table of Contents
- Authentication
- Setting up Fauna in Next.js
- Authentication and Authorization in Fauna
- NextAuth
- Requirements and Features
- Modelling the data
- Conclusion
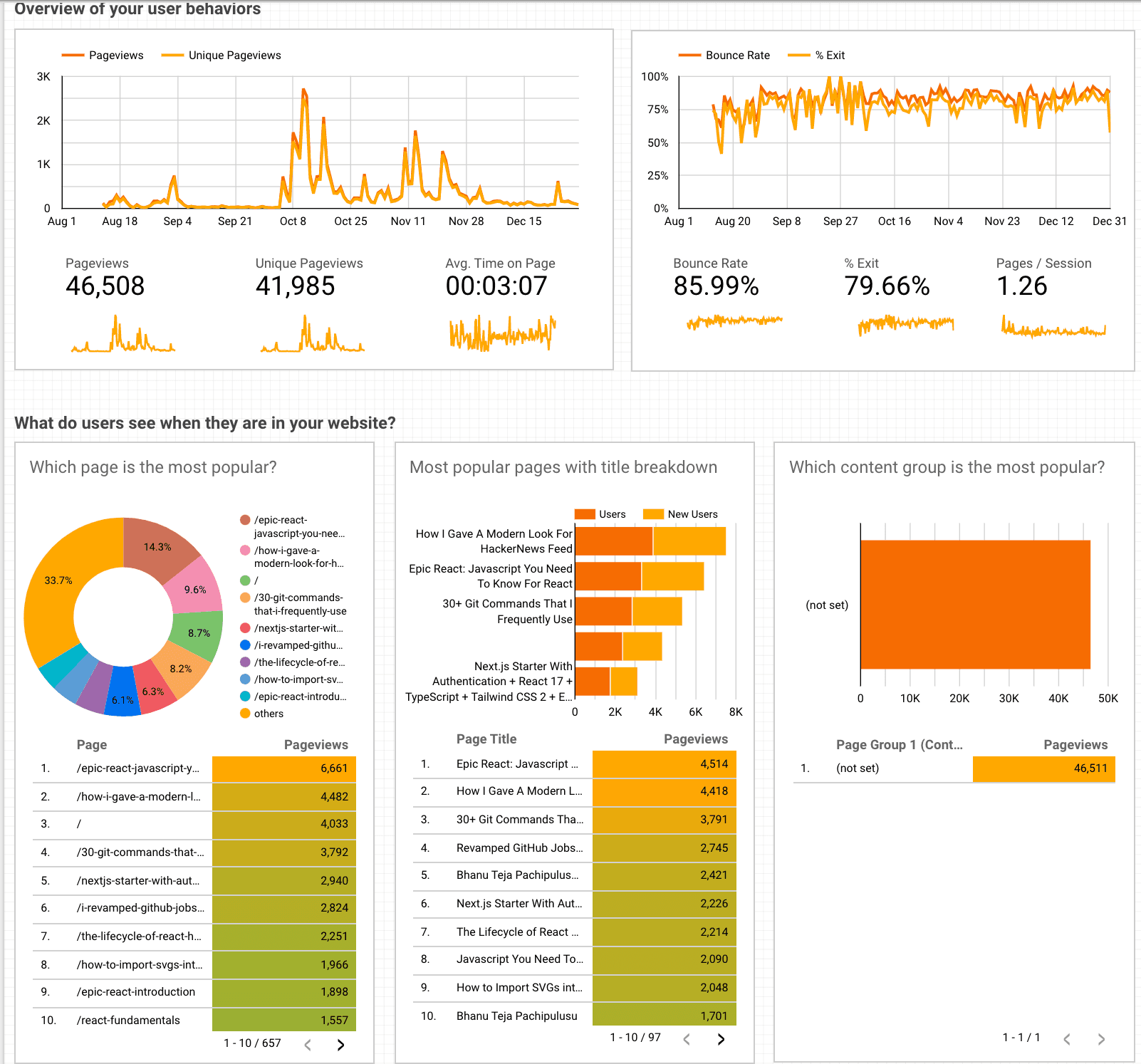
I have recently built a website for our local developer community Coderplex completely Serverless. We were able to start from scratch and got it launched within just 3 weeks of time. In this article, I will show what the website is about, how I built it, and also show the areas of improvement and the new features that we are planning to add to it.
The website is basically a platform like Twitter where you post updates. The only difference is that it's aimed towards developers(has things like markdown editor), and it's goal-centric. As soon as the users log in to the site, they will be prompted to set their goal. You will be asked to set a title for the goal, write the plan of action of how you want to achieve that goal, and finally, you will be asked to set a deadline, before which you intend to achieve that goal. After that, you will be allowed to post updates whenever you want, showing what you are doing in order to reach that goal.
Authentication
We only have one mode of authentication i.e., through GitHub login. We are using next-auth package for this.
Check out the following blog post which I published a few weeks ago to know more about setting up GitHub authentication using next-auth.
3 Simple Steps To Setup Authentication in Next.js
Setting up Fauna in Next.js
Installing Fauna
Before we go through other features of coderplex.org, let's see how I have set up my Fauna in Next.js and how my Fauna workflow is.
Install faunadb (javascript driver for Fauna DB) as a dependency in your Next.js project
yarn add faunadb
# npm install faunadb
While developing locally, you have two choices:
- You can either create a test database in the Fauna cloud directly.
- You can set up the Fauna Dev Docker container locally.
I personally have set up the Docker container and have been using that for local development.
To know more about setting up the Fauna Dev container, go to the relevant section in the documentation.
To summarize, here is what I have done.
# Pull the latest Docker image of faunadb
docker pull fauna/faunadb:latest
# Verify if it installed correctly
docker run fauna/faunadb --help
# Run the Fauna Dev
docker run --rm --name faunadb -p 8443:8443 -p 8084:8084 fauna/faunadb
# After this, the Fauna Dev is started locally at port 8443
If you go through the documentation, you will see that there are so many ways to run the Fauna Dev. I chose the first approach because I want to start with a fresh state every time I start the database. In this approach, as soon as you stop the container, all the data will be erased, and whenever you start the container again, you will be starting with a fresh instance of Fauna.
Setting up Migrations Tool
If you come from a background of Laravel/Django/Rails/Node, you are most probably be aware of migrations. In simple terms, the migrations are the set of files. They help manage the changes in the database schema. The files are usually associated with timestamps of the time when the migrations are created. There will usually be a way to apply a migration or rollback(unapply) a migration. These are incremental steps that you need to perform to get the fresh database to the same state as the current database.
In Fauna, there is no native solution to achieve this. But very recently, an unofficial tool has been created by a developer advocate at Fauna. I have been using that tool for setting up migrations in my projects.
# Install the tool as a dev dependency
yarn add -D fauna-schema-migrate
# If you use npm, run the following command to install it.
# npm install -D fauna-schema-migrate
# Initialize the folders and config needed for this tool
npx fauna-schema-migrate init
This will create some files and folders which we later use to set up migrations for the collections and indexes that we create. Go through the GitHub REAMDE to know more about this tool. To summarize, here's how it works.
- You add all your collections, indexes, etc in your
fauna/resourcesfolder. - Based on the changes in the resources folder, you will be able to generate migrations. These migrations will get generated in your
fauna/migrationsfolder. - You will have the ability to see the state of the database. You will be able to see what all migrations have been applied and what migrations are yet to be applied.
- You will be able to apply the migrations or rollback the applied migrations.
- While running any of these commands, you will be asked to enter the
FAUNA ADMIN KEY.- You will be able to generate this key from the Security tab of the Fauna dashboard.
- You can also set the environment variables
FAUNA_ADMIN_KEY,FAUNADB_DOMAIN,FAUNADB_SCHEME, andFAUNADB_PORT. - While connecting to the cloud database, you will only need to set
FAUNA_ADMIN_KEY. - If you are working with the Fauna Dev Docker container, you need to set up other variables too.
- Since I am using Fauna Dev for local development, I have set up these as per my configuration.
export FAUNA_ADMIN_KEY=secret # This is the default secret for Fauna Dev
export FAUNADB_DOMAIN=localhost
export FAUNADB_SCHEME=http
export FAUNADB_PORT=8443
Authentication and Authorization in Fauna
Fauna has its own authentication system. But in this project, I have been using a next-auth adapter for authentication. Basically what this means is that I will handle all the authentication and authorization elsewhere(in the serverless functions of my app), and only allow the users to access the resources that they are authorized to access. Doing things this way is definitely not ideal. Fauna offers a very powerful security system out of the box. But it's a bit tricky to make it work with next-auth system. But I am definitely planning to make use of Fauna's security system in the future and will try to make it work with next-auth without losing any of the capabilities of Fauna.
Next.js Serverless Function Setup for Fauna
This is how all my serverless functions look like in my Next.js app
Fauna DB Client Setup
I use Docker container locally, and use Fauna Cloud when the app is in production
import faunadb from 'faunadb'
// Checking if the app is in production
const isProduction = process.env.NODE_ENV === 'production'
// Using Fauna Dev Docker container when running locally
// Using Fauna Cloud when in production
const client = new faunadb.Client({
secret: process.env.FAUNADB_SECRET ?? 'secret',
scheme: isProduction ? 'https' : 'http',
domain: isProduction ? 'db.fauna.com' : 'localhost',
...(isProduction ? {} : { port: 8443 }),
})
Requires Authentication
If it requires the user to be authenticated, then I use next-auth getSession function to check if the user is authenticated.
import { getSession } from 'next-auth/client'
const Handler = async (req, res) => {
// If the user needs authentication
const session = await getSession({ req })
if (!session) {
return res.status(401).json({ message: 'Not logged in (UnAuthenticated)' })
}
// other code
// ...
// ...
// ...
}
export default Handler
Requires Authorization
If only a particular user is authorized to run this function, then I send the id of the authorized user in the request body, and manually check if the currently logged-in user is the same as that of the authorized user.
import { getSession } from 'next-auth/client'
const Handler = async (req, res) => {
// If the user needs authentication
const session = await getSession({ req })
if (!session) {
return res.status(401).json({ message: 'Not logged in (UnAuthenticated)' })
}
const { authorizedUserId } = req.body
const loggedInUserId = session.user.id
if (loggedInUserId !== authorizedUserId) {
return res.status(403).json({ message: 'Access Forbidden' })
}
// other code
// ...
// ...
// ...
}
export default Handler
Putting it all together, this is how a typical serverless function looks like in my nextjs app.
import { getSession } from 'next-auth/client'
import faunadb from 'faunadb'
const isProduction = process.env.NODE_ENV === 'production'
const client = new faunadb.Client({
secret: process.env.FAUNADB_SECRET ?? 'secret',
scheme: isProduction ? 'https' : 'http',
domain: isProduction ? 'db.fauna.com' : 'localhost',
...(isProduction ? {} : { port: 8443 }),
})
const q = faunadb.query
const Handler = async (req, res) => {
// If the user needs authentication
const session = await getSession({ req })
if (!session) {
return res.status(401).json({ message: 'Not logged in (UnAuthenticated)' })
}
const { authorizedUserId } = req.body
const loggedInUserId = session.user.id
if (loggedInUserId !== authorizedUserId) {
return res.status(403).json({ message: 'Access Forbidden' })
}
try {
const response: any = await client.query(
q.Do(
// Execute some fauna code here
)
)
// Some code
// ...
// ...
// ...
res.status(200).json(response)
} catch (error) {
console.error(error)
res.status(500).json({ message: error.message })
}
}
export default Handler
NextAuth
We need a few collections and indexes to work with next-auth's Fauna adapter. So, let's add those in fauna/resources folder. I have created two directories inside the resources folder. One is for collections and another for indexes.
These are the collections that I need for the next-auth's Fauna adapter.
// fauna/resources/collections/accounts.fql
CreateCollection({
name: 'accounts'
})
// fauna/resources/collections/users.fql
CreateCollection({
name: 'users'
})
// fauna/resources/collections/sessions.fql
CreateCollection({
name: 'sessions'
})
// fauna/resources/collections/verification_requests.fql
CreateCollection({
name: 'verification_requests'
})
Each of the above FQL queries is in a different file inside the resources/collections folder.
We also need a few indexes for the next-auth's Fauna adapter.
// fauna/resources/indexes/account_by_provider_account_id.fql
CreateIndex({
name: 'account_by_provider_account_id',
source: Collection('accounts'),
unique: true,
terms: [
{ field: ['data', 'providerId'] },
{ field: ['data', 'providerAccountId'] },
],
})
// fauna/resources/indexes/session_by_token.fql
CreateIndex({
name: 'session_by_token',
source: Collection('sessions'),
unique: true,
terms: [{ field: ['data', 'sessionToken'] }],
})
// fauna/resources/indexes/user_by_email.fql
CreateIndex({
name: 'user_by_email',
source: Collection('users'),
unique: true,
terms: [{ field: ['data', 'email'] }],
})
// fauna/resources/indexes/verification_request_by_token.fql
CreateIndex({
name: 'verification_request_by_token',
source: Collection('verification_requests'),
unique: true,
terms: [{ field: ['data', 'token'] }],
})
// fauna/resources/indexes/user_by_username.fql
CreateIndex({
name: 'user_by_username',
source: Collection('users'),
unique: true,
terms: [{ field: ['data', 'username'] }],
})
Now we need to generate the corresponding migrations for these resources. To do that, you can just run npx fauna-schema-migrate generate. This will create a new folder in the fauna/migrations folder, inside which there are files for each of the resource files that we created. You can apply all of these migrations in one go by running npx fauna-schema-migrate apply all.
Now that we are all set up, let's start working on the actual features of the application.
Requirements and Features
In coderplex.org app, each user will be able to do all of the following things:
- Goals
- Set a goal with title, description(goal plan – which also accepts MDX), and deadline.
- Currently, only 1 user will correspond to 1 goal. In other words, each goal will have a single participant, but in the future, multiple users can participate in the same goal. So the schema should take care of that.
- Updates
- Post an update to the goal
- An update is very similar to a tweet that you have on Twitter. The only difference is that each update will correspond to a goal.
- The update will also accept markdown(MDX).
- Edit your update
- Like any update
- Post an update to the goal
- Comments
- Add a comment to an update (also accepts MDX)
- Edit your comment.
- Like any comment
- Follow any other user
- Notifications
- Whenever another user likes your update/comment.
- Whenever another user follows you.
- Whenever another user comments on your update.
- Users should see the unread notification count.
- When they open the notifications, they should also be able to differentiate unread-notifications from read-notifications.
- All the notifications should be marked as read, by the next time they open the notifications, and the notification count should be reset to 0.
- Users should be able to edit/add the details like their social media links, their name, etc.
These are the requirements and features that we have in coderplex.org app.
Modelling the data
These are the following collections that I have created.
- goals
- goal_participants
- goal_updates
- update_likes
- update_comments
- comment_likes
- activities
- notifications
- notification_statuses
- user_followers
- users
Goals
This is how an example goal will look like. Each goal will have a reference to the user who created the goal.
{
"ref": Ref(Collection("goals"), "291155149010764290"),
"ts": 1614490198607000,
"data": {
"createdBy": Ref(Collection("users"), "291151577246335494"),
"title": "Learn NextJS",
"description": "I will go through the following resources......",
"timestamps": {
"createdAt": Time("2021-02-21T16:47:17.542336Z"),
"updatedAt": Time("2021-02-28T05:29:58.485254Z")
},
"deadline": Time("2021-03-12T00:00:00Z")
}
}
Goal Participants
Currently, the user who created a goal will be the only participant of the goal. But even if there are multiple participants of a goal, it will just be another new document in this collection. Each document of this collection will have a reference to the goal and also to the user collections.
{
"ref": Ref(Collection("goal_participants"), "291155149149176322"),
"ts": 1613926037910000,
"data": {
"goal": Ref(Collection("goals"), "291155149010764290"),
"participant": Ref(Collection("users"), "291151577246335494"),
"timestamps": {
"createdAt": Time("2021-02-21T16:47:17.542336Z"),
"updatedAt": Time("2021-02-21T16:47:17.542336Z")
}
}
}
Goal Updates
Each goal update will have reference to the goal to which this update belongs to, and also to the user who is posting this update.
{
"ref": Ref(Collection("goal_updates"), "291156218380026372"),
"ts": 1613927057530000,
"data": {
"goal": Ref(Collection("goals"), "291155149010764290"),
"postedBy": Ref(Collection("users"), "291151577246335494"),
"description": "Finished the \"Create a Next.js App\" section from the NextJS basics tutorial ",
"timestamps": {
"createdAt": Time("2021-02-21T17:04:17.345236Z"),
"updatedAt": Time("2021-02-21T17:04:17.345236Z")
}
}
}
Update Likes
Each document of this collection will have a reference to the user who performed this action and also to the update on which this action is performed on. Here the action is either like or unlike. Whenever a user likes an update for the first time, a new document is created in this collection, with liked set to true. Whenever the user unlikes an update, since the document is already created, we would just toggle the liked to false. Similarly, when the user likes the update for the second time after unliking, instead of creating a new document, liked is again set back to true.
{
"ref": Ref(Collection("update_likes"), "291156291484647936"),
"ts": 1613927127890000,
"data": {
"user": Ref(Collection("users"), "291150570318725632"),
"update": Ref(Collection("goal_updates"), "291156254585258502"),
"liked": true,
"timestamps": {
"createdAt": Time("2021-02-21T17:05:26.235891Z"),
"updatedAt": Time("2021-02-21T17:05:26.235891Z")
}
}
}
Update Comments
Each document in this collection will have reference to the user who posted this comment and also to the update under which this comment is posted.
{
"ref": Ref(Collection("update_comments"), "291226260758069760"),
"ts": 1613993855415000,
"data": {
"postedBy": Ref(Collection("users"), "291151577246335494"),
"update": Ref(Collection("goal_updates"), "291226189279789572"),
"description": "Nice job! ",
"timestamps": {
"createdAt": Time("2021-02-22T11:37:34.940974Z"),
"updatedAt": Time("2021-02-22T11:37:34.940974Z")
}
}
}
Comment Likes
A comment like is very similar to update_like, the only difference is that the user is liking/unliking a comment instead of an update.
{
"ref": Ref(Collection("comment_likes"), "291748514516435458"),
"ts": 1614491916980000,
"data": {
"user": Ref(Collection("users"), "291196688254632454"),
"comment": Ref(Collection("update_comments"), "291748498072666628"),
"liked": false,
"timestamps": {
"createdAt": Time("2021-02-28T05:58:34.974710Z"),
"updatedAt": Time("2021-02-28T05:58:36.839458Z")
}
}
}
Activities
Whenever an activity is performed, a new document will be created in this collection. An activity can be LIKED_UPDATE, UNLIKED_UPDATE, LIKED_COMMENT, UNIKED_COMMENT, COMMENTED, FOLLOWED, UNFOLLOWED. Each document in this collection will have a reference to the user who performed this activity and also to the resource, which has been added/changes as a result of this activity. For example, if the activity is LIKED_UPDATE, then the resource is from the update_likes collection because that is where we are storing the likes of the updates.
{
"ref": Ref(Collection("activities"), "291746021461983744"),
"ts": 1614489537610000,
"data": {
"user": Ref(Collection("users"), "291151577246335494"),
"resource": Ref(Collection("update_likes"), "291701773249282560"),
"type": "LIKED_UPDATE",
"timestamps": {
"createdAt": Time("2021-02-28T05:18:57.449934Z"),
"updatedAt": Time("2021-02-28T05:18:57.449934Z")
}
}
}
Notifications
This is the place where we store the notifications. Each document in this collection will have a reference to the user to which this notification should be shown. It will also have a reference to the activity based on which this notification is created. We will not create notifications for all the activities. For example, if one user unfollowed another user, we don't want to show that notification. So we only create notifications for some of the activities.
{
"ref": Ref(Collection("notifications"), "291746542632567300"),
"ts": 1614490034620000,
"data": {
"user": Ref(Collection("users"), "291299459214606850"),
"activity": Ref(Collection("activities"), "291746542630470148"),
"timestamps": {
"createdAt": Time("2021-02-28T05:27:14.492640Z"),
"updatedAt": Time("2021-02-28T05:27:14.492640Z")
}
}
}
Notification Statuses
In this collection, we store the number of notifications read by the user. Each document in this collection will have a reference to the user. This is how we will know how many unread notifications are present for a user. For example, if we have a total of 60 notifications for a user, and in notification_statuses collection, the same user has count as 58, then we know that the user has 2 new notifications, and we show the recent two notifications as unread in the UI.
{
"ref": Ref(Collection("notification_statuses"), "291746117445485062"),
"ts": 1615246280027000,
"data": {
"user": Ref(Collection("users"), "291150570318725632"),
"count": 58,
"timestamps": {
"createdAt": Time("2021-02-28T05:20:28.984137Z"),
"updatedAt": Time("2021-03-08T23:31:19.808558Z")
}
}
}
User Followers
This collection is very similar to the update_likes collection. Instead of liked, here you will have isFollowing. This will also have references to the user who is being followed, and also the user who is following the other user.
{
"ref": Ref(Collection("user_followers"), "291151670793994758"),
"ts": 1614489819630000,
"data": {
"user": Ref(Collection("users"), "291151577246335494"),
"follower": Ref(Collection("users"), "291150570318725632"),
"isFollowing": true,
"timestamps": {
"createdAt": Time("2021-02-21T15:52:00.472819Z"),
"updatedAt": Time("2021-02-28T05:23:39.192197Z")
}
}
}
Users
This is an example document in users collection.
{
"ref": Ref(Collection("users"), "292150540328725632"),
"ts": 1613940787978000,
"data": {
"email": "pbteja1998@gmail.com",
"image": "https://avatars.githubusercontent.com/u/17903466?v=4",
"account": {
"firstName": "Bhanu Teja",
"lastName": "Pachipulusu",
"bio": "Software Engineer"
},
"socials": {
"github": "pbteja1998",
"twitter": "pbteja1998",
"blog": "https://bhanuteja.dev/",
"facebook": "pbteja1998",
"linkedin": "pbteja1998",
"codepen": "pbteja1998",
"discord": "BhanuTeja#4468"
},
"otherDetails": {
"company": "Coderplex",
"userType": "yes",
"mobile": "9876543210",
"isCurrentlyWorking": "yes"
},
"username": "pbteja1998",
"timestamps": {
"createdAt": Time("2021-02-21T15:34:30.938680Z"),
"updatedAt": Time("2021-02-21T20:53:07.848454Z")
},
"loggedInFromCoderplexOrg": true
}
}
Conclusion
In this blog post, I have tried to explain how I use Fauna DB in my Next.js applications. I also showed how I modeled the data for the application. In the next blog post, I would write about different parts of the home page of the application, and also the queries to fetch the data required to show everything that is there on the home page.